

[译苑雅集Vol. 8]深入探索人工智能模型:从Transformer到扩散模型的演变
本文介绍了人工智能(AI)模型的最新进展,从大型语言模型(LLM)如GPT和Gemini,到基于扩散模型的图像生成技术。通过解析Transformer架构的注意力机制和扩散模型的物理原理,深入探讨了这些技术如何推动AI的进步和实际应用,包括推荐系统和未来AI模型的发展趋势。


作者:The Econnomist
时间:2024年8月6日
原文:https://www.economist.com/schools-brief/2024/08/06/how-ai-models-are-getting-smarter
在ChatGPT中输入一个问题,答案立刻呈现。向DALL-E 3输入提示词,一幅图像便会生成。点击TikTok的“为你推荐”页面,你会看到符合你口味的视频。向Siri询问天气,片刻之后便会有语音回应。这些都得益于人工智能(AI)模型的支持。这些模型大多依赖于神经网络,经过大量的文本、图像等信息训练,通过反复试验和调整神经元之间的连接权重,就像调整数十亿个旋钮,直到输出结果令人满意。
神经网络和架构创新
神经网络可以通过多种方式连接和分层。近年来,架构方面的一系列进展帮助研究人员构建了能够更高效学习并从现有数据集中提取更多有用信息的神经网络,推动了AI的进步。当前的研究重点集中在两大模型家族上:用于文本的大型语言模型(LLMs)和用于图像的扩散模型diffusion models。这些模型比之前的模型更深(即拥有更多层的神经元),并且组织方式使其能够快速处理大量数据。
Transformer架构与大型语言模型
诸如GPT、Gemini、Claude和Llama等大型语言模型都是基于所谓的Transformer架构。这种架构由谷歌大脑Google Brain的Ashish Vaswani团队在2017年引入,其关键原理是“注意力机制”。注意力层允许模型学习输入的多个方面(如文本中相距一定距离的词)之间的关系,并在生成输出时加以考虑。多层注意力层使模型能够在不同粒度级别上学习关联——从词语到短语甚至段落。这种方法也非常适合在图形处理单元(GPU)芯片上实现,推动了Nvidia等GPU制造商的市值提升。
扩散模型与图像生成
基于Transformer的模型不仅能生成文本,还能生成图像。OpenAI于2021年发布的首个版本DALL-E便是一个例子,这个模型学习了图像中像素组之间的关联,而非文本中的词语。在这两种情况下,神经网络都在将其“看到”的内容转化为数字,并对其进行数学运算(特别是矩阵运算)。然而,Transformer模型存在一些局限性。它们难以学习一致的世界模型。例如,当处理人类的查询时,它们的回答可能会前后矛盾,因为它们并不真正“理解”这些回答,只是关联了一些看似合理的词串。
众所周知,基于Transformer的模型容易出现所谓的“幻觉”,即生成看似合理但实际上错误的答案,并引用虚假的支持信息。类似地,早期基于Transformer的图像生成模型经常违反物理规则,生成一些不合理的图像(这可能对某些用户来说是特色,但对设计师而言却是一个缺陷,他们追求的是生成真实感图像)。因此,我们需要新的模型。
于是,扩散模型登场了,它能够生成更为逼真的图像。其核心理念受物理扩散过程的启发。我们将茶包放入一杯热水中,茶叶会开始浸泡,茶色会渗出,逐渐扩散到清水中。几分钟后,杯中的液体颜色会变得均匀。物理定律决定了这种扩散过程。正如你可以用物理定律预测茶如何扩散一样,你也可以逆向工程这一过程,重建茶包最初浸入的位置和方式。在现实生活中,热力学第二定律使得这一过程无法逆转;你无法从杯中恢复原始茶包。但学习模拟这一逆向过程使得逼真的图像生成成为可能。
训练过程如下:首先,对图像逐步添加模糊和噪声,直到其看起来完全随机。然后,困难的部分来了:逆转这一过程,重现原始图像,就像从茶中恢复茶包一样。这是通过“自监督学习”完成的,类似于大型语言模型(LLM)在文本训练中的方法:遮盖句子中的词语,通过反复试验学习预测缺失的词语。在图像的情况下,网络学习如何去除越来越多的噪声,以再现原始图像。通过处理数十亿张图像,学习去除失真所需的模式,网络获得了从纯随机噪声中创造全新图像的能力。
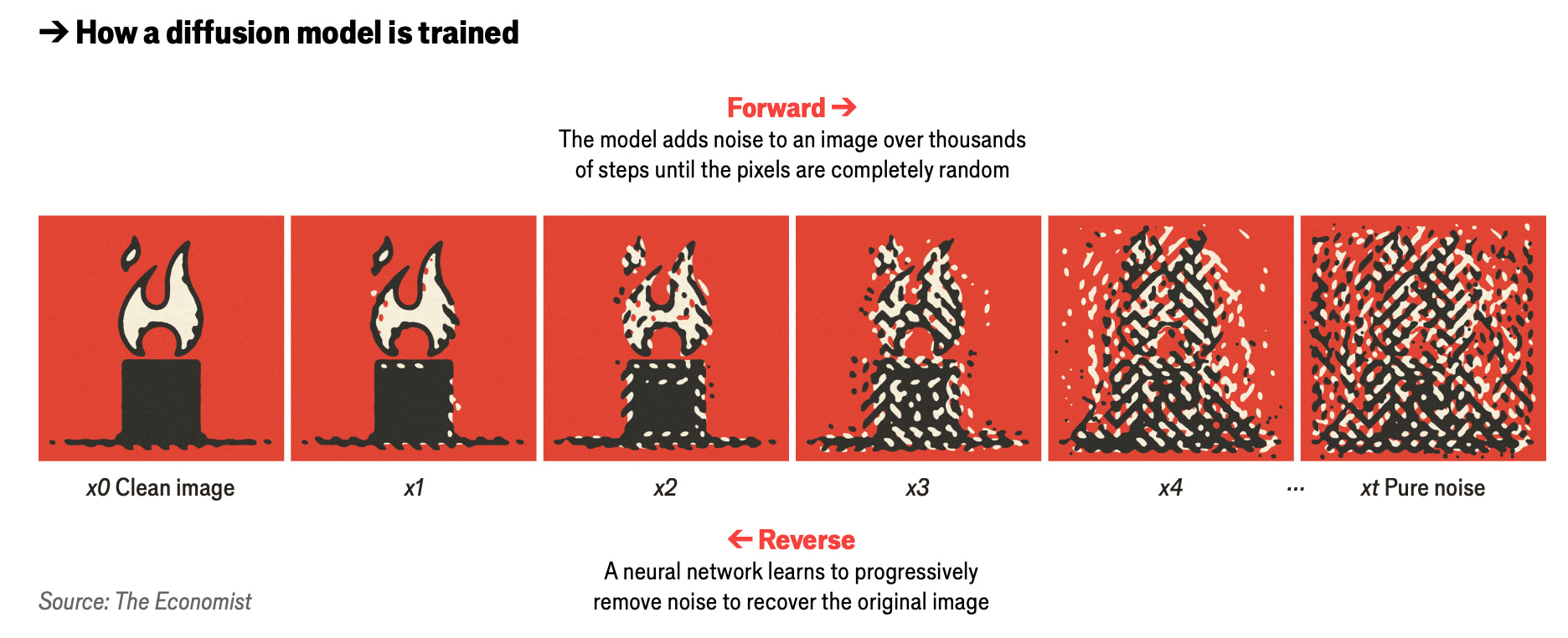
大多数最先进的图像生成系统使用扩散模型,尽管它们在去噪或逆转失真方面的方法各不相同。Stable Diffusion(由Stability AI发布)和Imagen(2022年发布)使用了一种称为卷积神经网络(CNN)的架构,该架构擅长分析像素的网格数据。CNN实际上是通过小滑动窗口在输入上上下移动,寻找特定的特征,如图案和角点。但尽管CNN在像素处理上表现出色,一些最新的图像生成器使用了所谓的diffusion transformer架构,包括Stability AI最新的模型Stable Diffusion 3。经过扩散训练后,Transformers模型能够更好地理解图像或视频帧的各个部分如何相互关联,以及它们之间的强弱关系,从而生成更为逼真的输出(尽管它们仍然会犯错误)。
推荐系统与深度学习
推荐系统是另一种复杂的应用领域。很少有人能一窥其内部工作原理,因为构建和使用推荐算法的公司对此高度保密。但在2019年,Meta(原Facebook)发布了其深度学习推荐模型(DLRM)的详细信息。该模型有三个主要部分。首先,它将输入(如用户的年龄、在平台上的“点赞”或消费内容)转换为“嵌入embeddings”。它以一种方式学习,使得类似的事物(如网球和乒乓球)在嵌入空间中彼此接近。
然后,DLRM使用神经网络进行矩阵分解。想象一个电子表格,其中列是视频,行是不同的用户。每个单元格显示每个用户对每个视频的喜好程度。但大多数单元格是空的。推荐的目标是对所有空单元格进行预测。DLRM可以通过将网格(在数学上,矩阵分解)分成两个网格来实现这一目标:一个包含用户数据,一个包含视频数据。通过重新组合这些网格(或矩阵相乘)并将结果输入另一个神经网络进行更多的数据处理,可以填充原来为空的单元格——即预测每个用户对每个视频的喜好程度。
同样的方法可以应用于广告、流媒体服务上的歌曲、电子商务平台上的产品等等。科技公司最感兴趣的是那些在商业上有用的任务上表现出色的模型。但大规模运行这些模型需要很多的资金、海量的数据和巨大的计算能力。
明年的模型会更精彩
在学术环境中,因为数据集较小且预算有限,其他类型的模型更为实用。这些模型包括递归神经网络(用于分析数据序列)、变分自编码器(用于发现数据中的模式)、生成对抗网络(一个模型通过不断尝试欺骗另一个模型来学习任务)和图神经网络(用于预测复杂交互的结果)。
正如深度神经网络、Transformer和扩散模型都从最初的研究走到了今天被广泛使用,这些其他模型的特性和原则也将被纳入未来的AI模型中。虽然Transformer非常高效,但尚不清楚仅仅继续扩展其规模,是否能解决其幻觉倾向和推理时的逻辑错误问题。目前,研究人员正在寻找“后Transformer”架构,从“状态空间模型state-space models”到“神经符号neuro-symbolic AI”,以克服这些弱点并实现下一次飞跃。理想情况下,这种架构将结合注意力机制和更强的推理能力。目前还没有人知道如何构建这种模型,也许有一天某个AI模型会完成这项工作。