

GenAI的进展与预测
两年半过去,GenAI 正从狂热走向理性。Scaling Law失效、Agent受限、AGI前路不明,本文详解当前大模型的科学瓶颈、产业现状和短期价值,同时拆解CoreWeave的商业模式,看清AI行业真正的赢家与挑战。


从 ChatGPT 发布至今已经过去了两年半,根据 Gartner 的 Hype Cycle 模型,GenAI 理应已经度过了期望膨胀期,逐渐步入更加理性的阶段。随着热度逐渐消退,我想更新一下自己对 GenAI 最新进展和未来趋势的看法。

Scaling Law 已撞墙
我们从岁末年初说起,DeepSeek 借助 V3 和 R1 模型成功追赶上了头部AI Lab,正式跻身第一梯队,V3模型达到了 GPT-4 水平。
为什么能做到?梁文锋和 DeepSeek 团队当然非常厉害,V3和R1 的能力也没得说,包括最近 DeepSeek 和清华大学合发的那篇论文,使用思考链的方式提高 强化学习 RL 里奖励函数的质量非常有创意。这一研究对提高后续 R2 模型的能力有很大帮助,特别是在 OpenAI 最新发布的 o3 思考模型出现过度优化问题的情况下,这种方法尤其值得关注。
但话说回来,DeepSeek 能赶上第一梯队的最主要原因是前沿 LLMs 的进展完全不达预期。GPT-4的预训练在2022年11月ChatGPT发布前就已经完成,按照23年初的计划时间线,大家现在应该用上 GPT-6了。但现实是:
2月底,OpenAI将传说中的GPT-5以GPT-4.5的名称低调发布,推测其参数量在 5T+,对比GPT-4 的参数量是1.8T。
未来也不会有GPT-5模型了,GPT-5会是一款整合所有OpenAI现有模型的产品。
同期和后续发布的 xAI Grok 3、Google Gemini 2.5、Anthropic Claude 3.7、Meta Llama 4,通通没能戴上超越GPT-4的NG-LLM桂冠。
4月初,OpenAI发布GPT-4.1时宣布GPT-4.5将在7月14日从API服务中移除。
也就是说 Scaling Law 推崇的更多数据、更大算力,训练更大参数模型的的暴力路线已经基本达到极限。
现在参数量最大的LLM是GPT-4.5,使用一段时间后我的感受是它确更“懂人话”,对文字细微差别的理解提升明显,但4o不擅长的它还是不擅长。
LLMs的科学缺陷:基于经验给出最“像”的答案
今年的美国数学奥林匹克(USAMO)于 3 月 19–20 日举行。比赛结束仅数小时后(几乎不可能存在数据泄露的可能),一组科学家将试题交给了一些声称具有强大数学与推理能力的主流大语言模型,包括:o3-Mini、o1-Pro、DeepSeek R1、QwQ-32B、Gemini-2.0-Flash-Thinking-Exp,以及 Claude-3.7-Sonnet-Thinking。这些模型生成的证明解答由专家进行了评估。
结果相当惨淡:没有任何一个 AI 模型的总得分超过 5%。
“人类参赛者最常见的失败模式是无法找到正确解法。通常情况下,人类会清楚自己是否解决了问题。而与之相反的是,所有被评估的大语言模型都一致地声称自己解决了问题。”

这再次揭示了大模型在输出质量上高度依赖于训练样本,也暴露了其自 GPT-3 起就存在的根本性缺陷:大模型本质上是在基于经验给出“看起来最像正确答案”的回答。它们没有“我知道”或“我不知道”的意识,不具备元认知能力,因此也不会意识到自己的无知。在面对所有问题时,它们总是信心满满,却极少说出那句关键的话——“我不知道”。
Agent 呢?卡在技术、安全和法律的三重门
既然预训练大模型的发展已经明显放缓,那最近颇受关注的 Agent(智能体)会不会是新突破口?
现在最成熟的 Agent 应该算基于互联网搜索的 Deep Research产品,ChatGPT 和 Gemini 都有,我的使用感受是:
不懂的领域:厉害,好牛;
略懂的领域:初看像那么回事,看完也就公众号水平。
此外,另两个具备网页访问能力的 Agent——ChatGPT Operator 和 Manus,用起来就像是以前那个偶尔抽风的“键盘精灵”。相较传统 NLP 自动化流程,它们的稳定性和可靠性仍然太低。
另一方面,在去年的 WWDC 上,Apple 发布了自家的大模型能力 Apple Intelligence,并带来了由其驱动的新 Siri。本计划随 iOS 18 一同上线,但从 18.1 一路跳票到 iOS 19,坊间传闻称原因是——安全问题难以解决,尤其是 Prompt Injection 攻击,导致系统稳定性和隐私风险难以控制。
而这恰恰反映了通用泛化型 Agent 的核心问题:它的自主性远高于 L4 级别的自动驾驶系统。最近几起涉及辅助驾驶的严重交通事故,再次引发了“技术产品事故责任归属”的广泛讨论。而通用 Agent 在这方面的挑战只会更复杂。出了问题,责任该归谁?是产品责任?开发者责任?用户责任?当前的法律体系对此完全没有准备。
现在谁赚到大钱了?CoreWeave 的 IPO
这波 AI 浪潮中,最先赚到大钱的当然还是英伟达。但上个月底,另一家关键玩家登场:AI 第一股 CoreWeave(股票代码 CRWV)于 3 月 28 日在纳斯达克上市,IPO 时市值约为 230 亿美元,最高时曾冲到 320 亿美元,堪称近期市场上的明星公司。


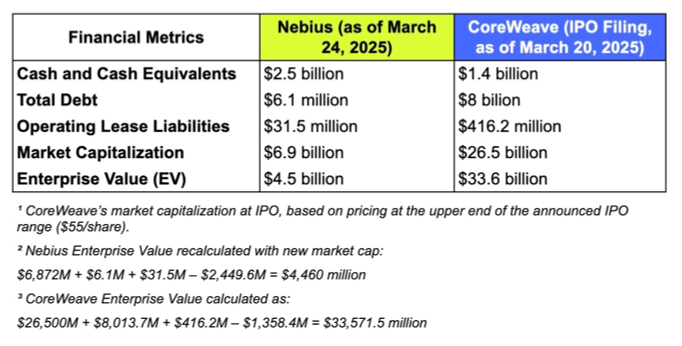
CoreWeave 最初并不做 AI,而是起家于加密货币挖矿。2022 年,它转型为专注于 AI 计算资源的服务商。收入增长堪称惊人:2022 年营收仅为 1500 万美元,2023 年暴增至 2.28 亿美元,2024 年再跃升至 19.15 亿美元。如今,公司已部署超过 25 万块 GPU,在手订单超过 150 亿美元。
听上去是不是很猛?但我们不妨看看它到底做的是什么生意——说白了,就是最传统的设备租赁。
更具体地说,CoreWeave 与大型互联网公司和 AI 实验室签订多年期的“照付不议”(pay-or-take)合同锁定需求。例如,它与OpenAI签下了长达五年、总额达 119 亿美元的合作协议,仅 2024 年,微软就贡献了其 62% 的收入。锁定需求和未来现金流之后,CoreWeave再以此为基础,通过结构化金融工具(如延期提款定期贷款 DDTL)获取供应链融资。凭借天量采购能力,它从英伟达手中优先获得最新一代 GPU 供货,然后迅速部署为裸金属服务器(服务器合作伙伴包括 Dell 和 SuperMicro),以租赁方式交付给客户。
这套商业模式的核心不是技术,而是资本结构——说得更直白一点,是把 GPU、网卡这类高价值硬件资产给“证券化”了。
归根结底,CoreWeave 做的是“淘金潮里卖铲子”的经典生意,只不过这次铲子是 GPU,租出去的,是算力。
短期来看,GenAI 的用处?
既然 AGI / NG-LLM在缺乏新的科学突破的情况下,靠工程手段优化已难有质变;同时通用泛化型 Agent 又卡在技术、安全和法律的三重门槛上,那短期内,LLM到底能干什么?
答案是:作为现有应用的一部分,为它们解锁新功能,或以更高的质量和效率提供已有功能。
说到这,就不得不提近期被频繁提及的 MCP(Model Context Protocol)。作为连接 LLM 与外部数据、工具的标准接口协议,MCP 被誉为 AI 时代的 “USB-C”。Google 也是不愿意让Anthropic专美于前,刚发布了一个新的 A2A (Agent-to-Agent)协议,用于规范 Agent 之间的通讯。

Source: https://weaviate.io/blog/what-are-agentic-workflows
网络安全行业对MCP 的安全性已经有了很多的研究,从架构和生命周期的角度都有非常多的安全问题需要处理。

Source: https://arxiv.org/pdf/2503.23278, Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
其中最具挑战性的安全问题,就是 Prompt Injection。这类攻击的复杂性与广泛性甚至超越了经典的 SQL 注入。当前通用做法是对 LLM 输入输出两端进行过滤与检查,一旦识别出 Prompt Injection 或其他风险(如信息泄露)则触发拦截或告警。
但与 SQL 注入不同,Prompt Injection 的攻击门槛极低,攻击者不需要任何技术背景,“只要会打字”。这使得传统基于特征匹配或正则表达式的防御手段难以奏效。
尽管有厂商尝试使用 AI 本身作为防御手段,例如 Meta 推出的 Llama Guard 采用 LLM 来分析输入/输出内容,但由于 AI 是“可能性驱动”的技术,同一个 prompt 可能每次结果都不同,导致防御结果并不稳定。AI 对抗仍然前景堪忧。
Google DeepMind 最近发布的一篇论文则提出了一个“双层 LLM 架构”,试图用更复杂的系统设计来限制 Prompt Injection 的危害。本质上是用传统软件架构和安全机制去框住 LLM 的自由发挥能力,也从侧面体现了解决这个问题的难度。

Source: https://arxiv.org/pdf/2503.18813, Defeating Prompt Injections by Design
总结
用“像人”来衡量 AGI,本身就是一种误导,甚至是一种人类中心主义的傲慢。走向 AGI 的路径将越来越“场景化”,而“AGI”这个宏大概念本身,未来可能会逐渐淡出主流叙事。
科学探索还远未到终点。基于 Transformer 架构的大模型,很可能只是 AGI 演化史上的“尼安德特人”——强大,但非终局。
通用泛化型 Agent,在技术上尚不稳定,在安全上充满不确定性,在法律层面更是存在难以逾越的障碍。真正意义上的自主 Agent,恐怕短期内难以落地。
在目前的 LLM 水平下,AI 工厂生产的 tokens 更像是一种新型基础设施,将像电力一样逐步渗透整个互联网。但回顾历史,人类从传统能源转向电力,走了整整一个世纪。
可预见的未来里,LLMs 最有价值的角色,并不是作为“超级智能体”独当一面,而是作为现有系统的一部分:提升效率,拓展能力,解锁新的可能性,特别是在文本处理、场景决策和工具联动等领域。
构建基于 LLM 的应用时,务必秉持“能简单就不要复杂”的原则。系统架构上保持克制,只有在确有必要时,才引入额外的复杂度。